

前言
本文将针对信息过载阅读搜索难的问题,展示如何利用OpenAI API高效地自动总结PDF,从而提高阅读效率和节省时间。包含详尽的操作教程、实际案例及最佳实践,旨在确保准确且高效地进行文档摘要。另外,本文还将深入探讨运用AI技术进行PDF总结的优势,如提高生产力、节省时间等,同时分析了在实际应用中可能遇到的局限性和挑战。
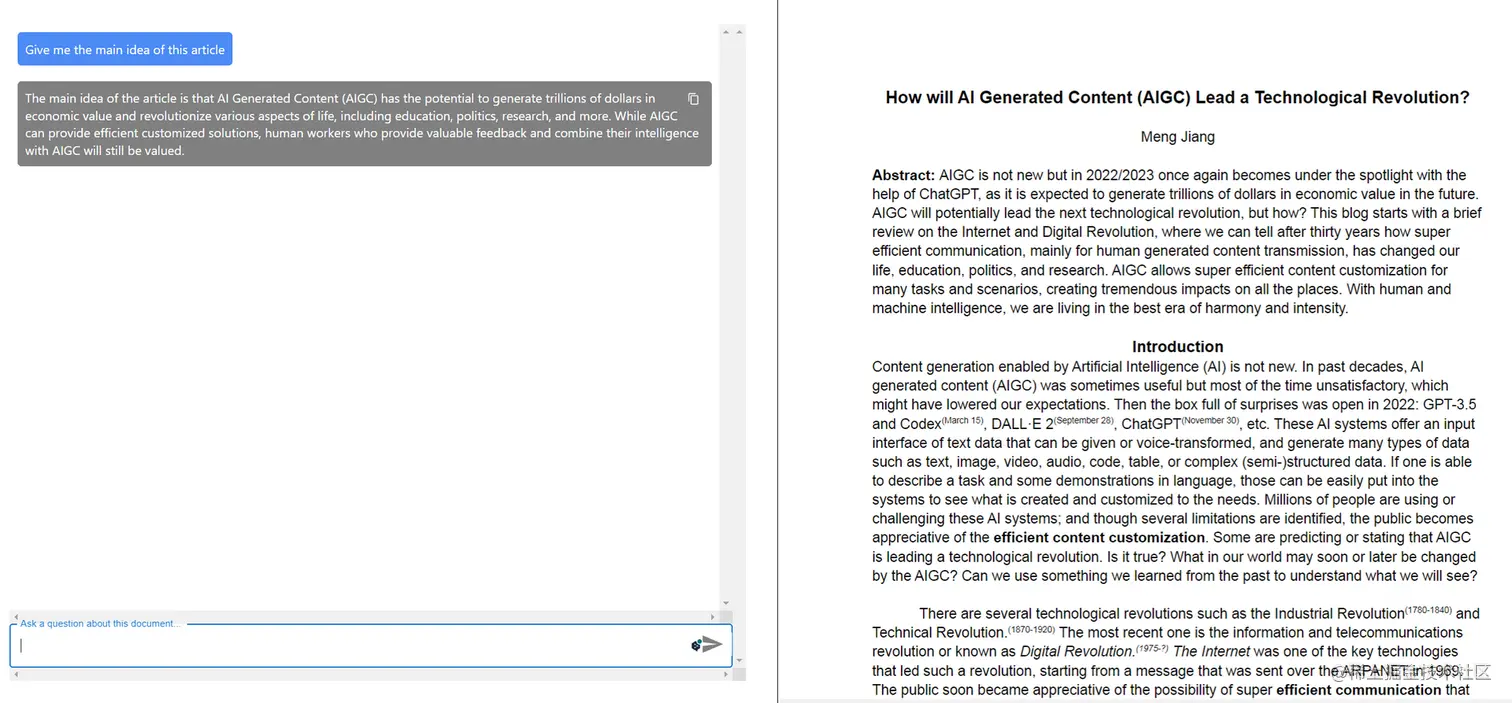
通过本文,可帮助您简化阅读过程,提高处理大量信息的能力,从而提升工作效率和学术表现,更好地应对快节奏世界中的信息挑战,充分利用AI技术为您的阅读和学习带来更多便利。
环境准备
在开始前,我们要准备好开发开发环境,首先你要准备好Openai的访问密钥,提供文本总结的能力。
其次你要准备python语言的开发环境,并且安装Fitz库,A该库将提供读取、写入和操作PDF文件的能力。
pip复制代码pip install PyMuPDF openai
然后将必要的库引入到Python文件中。
python复制代码import fitz
import openai
读取pdf内容
python复制代码import fitz
import openai
context = ""
with fitz.open(‘filename.pdf’) as pdf_file:
num_pages = pdf_file.page_count
for page_num in range(num_pages):
page = pdf_file[page_num]
page_text = page.get_text()
context += page_text
- 创建一个名为Context的变量,将其设置为空字符串。此变量将用于存储整个PDF文档的文本内容。
- 使用Fitz库的fitz.open()函数打开PDF文件。此函数将PDF文件名作为参数。
- 使用pdf_file对象的page_count属性获取PDF文件中的总页数。这将用于循环遍历PDF文件中的每一页。
- 使用for循环遍历PDF文件中的每一页。循环从0开始,到num_pages – 1结束,因为Python的数组索引从0开始。
- 在循环内部,使用pdf_file对象获取当前页面。page_num变量用于索引PDF文件中的页面。
- 使用页面对象的get_text()方法提取当前页面的文本内容。此方法返回包含页面文本的字符串。
- 使用+=运算符将当前页面的文本追加到Context变量。这将文本添加到Context字符串的末尾。
- 在循环完成后,Context变量将包含整个PDF文档的文本内容。
分解pdf成段落
下一步是将pdf的内容输入 split_text 函数,该函数负责将文本划分为每段包含5000个字符的段落。
python复制代码
def split_text(text, chunk_size=5000):
“””
Splits the given text into chunks of approximately the specified chunk size.
Args:
text (str): The text to split.
chunk_size (int): The desired size of each chunk (in characters).
Returns:
List[str]: A list of chunks, each of approximately the specified chunk size.
“””
chunks = []
current_chunk = StringIO()
current_size = 0
sentences = sent_tokenize(text)
for sentence in sentences:
sentence_size = len(sentence)
if sentence_size > chunk_size:
while sentence_size > chunk_size:
chunk = sentence[:chunk_size]
chunks.append(chunk)
sentence = sentence[chunk_size:]
sentence_size -= chunk_size
current_chunk = StringIO()
current_size = 0
if current_size + sentence_size < chunk_size:
current_chunk.write(sentence)
current_size += sentence_size
else:
chunks.append(current_chunk.getvalue())
current_chunk = StringIO()
current_chunk.write(sentence)
current_size = sentence_size
if current_chunk:
chunks.append(current_chunk.getvalue())
return chunks
- 该代码定义了一个名为
split_text的 Python 函数,用于将较长的文本分割成大小相近的较小块。 - 函数使用
sent_tokenize函数将文本分割成句子,然后遍历每个句子以创建块。 - 每个块的大小可以在函数参数中指定,默认大小为5000个字符。
- 该函数返回一个块列表,每个块的大小约为指定的大小。 这个函数可以用于对较长的 PDF 文本进行摘要处理,将它们分解成容易处理的较小块。
总的来说,split_text函数将冗长的PDF文本分解成可管理的段落,以便进行归纳总结,使其更容易处理和提取关键信息。
用OpenAI模型归纳总结文本段落
python复制代码def gpt3_completion(prompt, engine=’text-davinci-003', temp=0.5, top_p=0.3, tokens=1000):
prompt = prompt.encode(encoding=’ASCII’,errors=’ignore’).decode()
try:
response = openai.Completion.create(
engine=engine,
prompt=prompt,
temperature=temp,
top_p=top_p,
max_tokens=tokens
)
return response.choices[0].text.strip()
except Exception as oops:
return “GPT-3 error: %s” % oops
def gpt3_completion(prompt, engine='text-davinci-003', temp=0.5, top_p=0.3, tokens=1000)这个函数接受一个提示字符串和四个可选参数:engine,temp,top_p 和 tokens。promptprompt.encode(encoding='ASCII',errors='ignore').decode()将提示字符串编码为 ASCII 格式,并在编码过程中忽略可能出现的任何错误,然后将其解码回字符串。 3.try:和except Exception as oops:用于处理在执行 try 块内的代码时可能出现的任何错误。response = openai.Completion.create(...)向 OpenAIGPT-3 API发送请求,根据提供的prompt、engine、temp、top_p 和 tokens 参数生成文本补全。响应结果存储在 response 变量中。return response.choices[0].text.strip()从响应对象中提取生成的文本,并删除任何前导或尾随的空白字符。- 如果在执行 try 块期间发生错误,函数将返回一个包含错误信息的错误消息。
总结
总的来说,本文实现的能力极大地简化阅读过程。通过使用 Fitz 库和 OpenAI 的 GPT-3 语言模型我们可以轻松地从 PDF 文件中提取并总结关键信息。另外,本文使用的是GPT-3模型,如果使用GPT-4模型那效果更佳,特别是2023年6.13以后的模型版本更出彩。
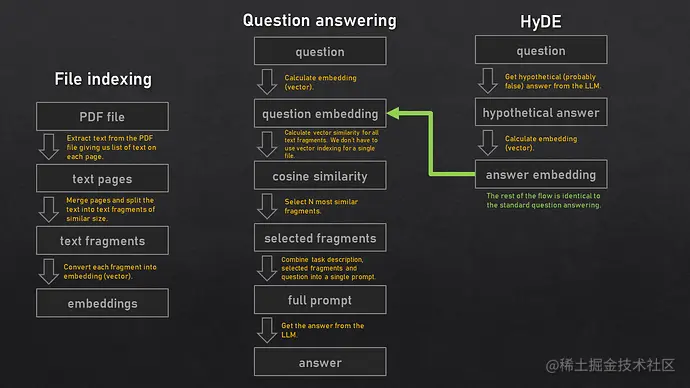
当然,本文只是为实现pdf的总结提炼提供一个思路,如果是工程级别,其中还要考虑到处理文件页数足够的多怎么办,如何索引目录以及内容,如何避免模型胡诌,如何提供隐私加密等等。其中可能要用到Embedding,提示工程,加密等技术,可参照上图的大体流程,我们放在后面的文章讨论。
