

6月14日凌晨,OpenAI发布了几项重大更新,其中就包括一项名为「函数调用」的功能更新。
这项全新功能得到了众多网友——尤其是开发者的青睐,纷纷表示这将极大地帮助他们更好地使用API,以及更好地与自己的工具无缝集成。

那么,函数调用功能究竟有什么神奇之处,能让众多开发者为之狂喜呢?
通过阅读本文,你将:
- 了解函数调用的基本原理,以及可运用的场景;
- 了解函数调用功能的基本实现步骤;
- 了解函数调用请求内容的格式规范,以及参数意义;
- 了解函数调用响应内容的提取方法,以及结果判断;
- 了解函数调用对于开发者的意义,以及可能的风险。
函数调用是什么?
函数调用是一种让模型能够智能地选择并执行外部函数的新方法。
开发者只需要向模型描述他们提供的函数,模型就能根据用户输入,判断需要调用哪一个函数,并输出一个包含所需参数的 JSON 对象。
这样,就能使 GPT 的功能与外部的工具和 API 更紧密地连接起来。
新的模型经过微调,既能识别用户输入中的函数调用意图,又能生成符合函数签名的 JSON 对象。
函数调用使开发者能够更可靠地从模型中获取结构化的数据,比如:
创建调用外部工具来回答问题的聊天机器人
例如:
| 输入 | 函数 | 外部工具 |
|---|---|---|
| 给 Anya 发电子邮件,看看她下周五是否想喝咖啡 | send_email(to: string, body: string) | 邮件发送工具 |
| 波士顿的天气怎么样? | get_current_weather(location: string, unit: ‘celsius’ | ‘fahrenheit’) | 天气查询工具 |
将自然语言转换为 API 调用或数据库查询
例如:
| 输入 | 函数 | 类型 |
|---|---|---|
| 我的本月前十名客户分别是谁? | get_customers(min_revenue: int, created_before: string, limit: int) | 内部API查询 |
| Acme, Inc. 上个月下了多少订单? | sql_query(query: string) | 数据库查询 |
从文本中提取结构化数据
例如:
| 文本 | 函数 | 目的 |
|---|---|---|
| (某篇维基百科文章) | extract_people_data(people: [{name: string, birthday: string, location: string}]) | 提取文章中提到的所有人 |
函数调用的基本步骤顺序
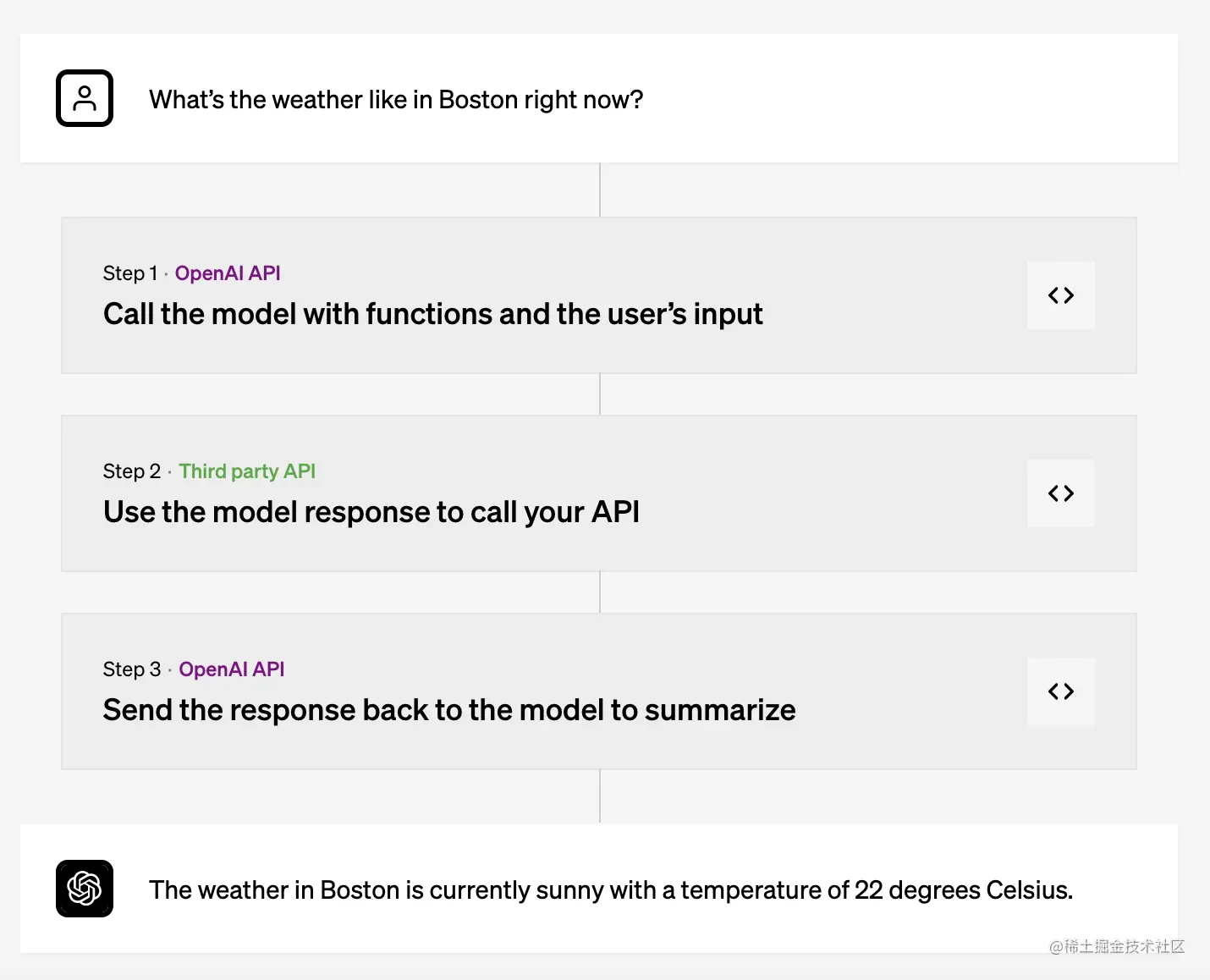
步骤1:使用函数和用户输入调用模型
我们需要将用户输入的指令,以及我们提供的一组预定义的函数,作为参数传入并调用模型。
python复制代码# 一个虚拟的函数示例,总是返回相同的天气信息
# 在真实的场景中,这可能是你的后端 API 或者外部 API
def get_current_weather(location, unit="fahrenheit"):
"""Get the current weather in a given location"""
weather_info = {
"location": location,
"temperature": "72",
"unit": unit,
"forecast": ["sunny", "windy"],
}
return json.dumps(weather_info)
def run_conversation():
# 将会话历史与可用的函数发送到 GPT
messages = [{"role": "user", "content": "What's the weather like in Boston?"}]
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
functions=functions,
function_call="auto", # auto 是默认值,但我们会明确说明
)
步骤2:使用模型响应调用 API
模型会根据用户输入,选择一个合适的函数,并返回一个包含参数的JSON字符串作为响应。
我们需要先将模型返回的字符串解析为JSON对象,再调用相应的函数并传入需要的参数。
ini复制代码 response_message = response["choices"][0]["message"]
# 检查 GPT 是否要调用函数
if response_message.get("function_call"):
# 调用函数
# 注意:JSON 响应不一定总是有效,务必处理错误
available_functions = {
"get_current_weather": get_current_weather,
} # 在这个例子中只有一个函数,但你可以有多个
function_name = response_message["function_call"]["name"]
fuction_to_call = available_functions[function_name]
function_args = json.loads(response_message["function_call"]["arguments"])
function_response = fuction_to_call(
location=function_args.get("location"),
unit=function_args.get("unit"),
)
步骤3:将响应发送回模型进行汇总
最后,我们将函数的返回结果作为新的消息附加到会话中,然后再次调用模型,让模型生成一个更完整的回复,并返回给用户。
ini复制代码 # 将函数调用和函数响应的信息发送给GPT
messages.append(response_message) # extend conversation with assistant's reply
messages.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
) # 用函数响应扩展会话
second_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
) # 从 GPT 获得一个新的回复,它可以在其中看到函数响应的内容
return second_response['choices'][0]['message']['content']
print(run_conversation())
新的回复内容如下:
The weather in Boston is currently sunny and windy with a temperature of 72 degrees.
与函数调用相关的API说明
Chat Completions API 是一个专门为多轮对话设计的API,它可以接收一个消息列表作为输入,并返回模型生成的消息作为输出。
典型请求格式
ini复制代码import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
model参数
表示要使用的模型ID,不同版本的模型支持不同的API功能。比如要支持函数调用功能,则必须是 gpt-3.5-turbo-0613 或 gpt-4-0613 及之后的版本。
messages参数
表示到目前为止,构成会话的消息列表。消息列表是一组消息对象,其中每个对象都包含一个角色和一条内容。
| 角色 | 职责 | 可选性 |
|---|---|---|
| system(系统消息) | 指定模型整体的语言风格或者助手的行为 | 可选 |
| assistant(助手消息) | 根据用户消息要求内容,以及系统消息的设定,输出一个合适的回应 | 可选 |
| user(用户消息) | 给出一个具体的指令 | 可选 |
支持函数调用的请求格式
ini复制代码import openai
messages = [{"role": "user", "content": "What's the weather like in Boston?"}]
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
functions=functions,
function_call="auto",
)
functions参数
用于提供函数规范,使模型能够生成符合所提供规范的函数参数。
| 参数 | 说明 |
|---|---|
| name | 要调用的函数的名称 |
| description | 对函数作用的描述 |
| parameters | 函数接受的参数,以 JSON 对象描述 |
function_call参数
用于控制模型如何响应函数调用。
| 可选值 | 说明 |
|---|---|
| none | 强制模型不使用任何函数 |
| {“name”: “my_function”} | 强制模型调用指定函数 |
| auto(默认值) | 由模型自己决定何时调用哪个函数 |
典型响应格式
css复制代码{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "The 2020 World Series was played in Texas at Globe Life Field in Arlington.",
"role": "assistant"
}
}
],
"created": 1677664795,
"id": "chatcmpl-7QyqpwdfhqwajicIEznoc6Q47XAyW",
"model": "gpt-3.5-turbo-0613",
"object": "chat.completion",
"usage": {
"completion_tokens": 17,
"prompt_tokens": 57,
"total_tokens": 74
}
}
content参数
在 Python 中,可以使用 response['choices'][0]['message']['content'] 提取来自助手消息的回复。
finish_reason参数
每个响应都会包含一个 finish_reason,其可能值为:
| 可能值 | 说明 |
|---|---|
| stop | API 返回完整消息 |
| length | 由于参数或标记限制,模型输出不完整 |
| function_call | 模型决定调用一个函数 |
| content_filter | 由于触发了来自我们内容过滤器的标记,而省略了内容 |
| null | API 响应仍在进行中或未完成 |
总结
你可能已经发现了,模型实际上并不会执行任何函数的调用。它只会根据用户的输入以及提供的函数,判断需要调用哪一个函数,并输出一个包含所需参数的 JSON 对象。
而开发者才是根据模型输出进行函数调用的真正执行者。
本质上,函数调用和第三方插件一样,都是用来扩展 GPT 模型的功能的,两者都是利用了 GPT 的以下能力:
- 知道何时需要利用外部工具解决问题的能力;
- 输出代码、表格、JSON等结构化数据的能力;
只不过,以前要实现这个目的,还需要借助第三方插件,再由第三方插件调用外部工具或内部API,现在,则相当于省去了第三方插件这一步,直接就可以调用了。
通过把这套函数规范接入到正式的调用流程,可以极大地提升开发 GPT 应用的灵活性,省去编写复杂提示的过程,提升反应速度的同时,也减少出错的可能性。
但是,这种能力也带来了潜在的风险,强烈建议在代表用户采取行动(如发送电子邮件、发布内容、进行购买等)之前,得到用户的进一步确认。
另外,函数是以特定的语法注入到系统消息中的,这意味着函数也会受模型上下文的限制,并计入输入标记的计费规则。建议实际开发中要限制函数的数量,以及为函数参数所提供的文档的长度。
